
Rendered.ai is a platform for generation, management, and analytics of synthetic image and video datasets. The generation engine applies physics to a virtual 3D scene and uses simulated sensor models to create images that emulate real-world output of scenes containing similar objects and backgrounds.
Request access to Rendered.ai!
TAO with Synthetic Data | NVIDIA NGC
Jupyter Notebook for training FasterRCNN with Rendered.ai user generated datasets.
Whether in the field of robotics, smart city, Synthetic Aperture Radar, X-ray, or remote sensing, synthetic data is pivotal in training and testing ML models used for object detection, semantic image segmentation, and pose estimation. Organizations use Rendered.ai to generate synthetic datasets that provide automated annotated image or video data to help them overcome issues such as:
- Error prone and expensive annotation of existing datasets
- Limited data, data with poor distributions for training, or missing data for edge case scenarios
- Environmental obstruction (e.g. snowy, low light)
- Sensitive data (e.g. medical, sports, security applications)
Using the Rendered.ai platform to design and generate synthetic data gives users the opportunity to iteratively evaluate generated data, adjust the generation steps, and incrementally optimize the performance of models trained on the output data. With NVIDIA TAO and data generated by Rendered.ai, a virtuous cycle is possible where the classifier’s performance leads to improved training data for the classifier (the green items in the image below). Additional opportunities for synthetic data closed-loop ML can be incorporated into a workflow via Renered.ai’s dataset analytics (in blue).
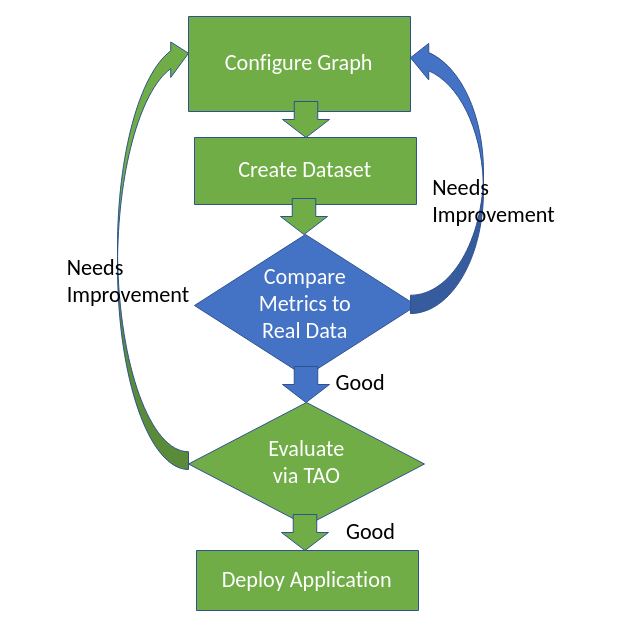
To leverage closed-loop ML with synthetic data, users change features of the “graph”, the generation engine configuration, to create datasets with designed properties. For example, a user could measure the sensitivity to object obstruction of a Faster R-CNN model by changing the “graph” to include more distractors or piling up objects of interest. The Faster R-CNN model would be trained on a synthetic dataset and then tested on several different synthetic datasets with varying obstruction levels. These synthetic datasets can be created with Rendered.ai’s free, open source example channel.
In the following section, we demonstrate how you can use synthetic data generated by Rendered.ai with training a ResNet-18 object detection model in TAO to quantify the dependency of object detection accuracy on the level of obstruction. The demonstration is captured in a Jupyter Notebook, obstruction_fasterrcnn, hosted on the NVIDIA NGC Catalog: ana_tao. Besides the effect of modifying graph parameters on a mAP performance metric, the notebook shows the user how to leverage inference visualizations to make informed updates to the graph for generating improved datasets.
Rendered.ai’s Example Channel
All users of Rendered.ai are provided an example channel. While meant to demonstrate how to use the platform to generate synthetic data, the Example Channel also can be used for object detection tasks, such as detecting various classes of toys in images of a box of party favors.

Read more about the Rendered.ai user interface at https://support.rendered.ai/.
In particular, the graphs for the example channel expose these features for control:
- Dataset Size — create the number of image/videos for a given graph
- Object Categories — adding extra objects as distractions
- Object Style — more colors; add randomization
- Domain Randomization — add floors / containers
- Obstruction Level — number of objects
- Perspective — Camera location, angle
- Lighting — Brightness and position of lamps
- GAN style transfer
With Rendered.ai, a user can create graphs and generate multiple datasets to explore the variance of a Faster R-CNN model.

Measuring OD Sensitivity to Obstruction
Object detection accuracy is highly dependent on level of obstruction. In the notebook, the obstruction level can be measured in terms of occlusion level and truncation as defined by the KITTI annotation format. The obstruction level, or average object obstruction level, of a dataset is the average over all the objects a normalized sum of the truncation and occlusion. For a dataset with N objects,

So an obstruction value of 0 means all the objects in the dataset are in full view, while a value of 1 would mean all the objects are completely covered (e.g. by distractors). By changing the number of objects in the scene we control the average object obstruction level of the dataset. The evaluation of a classification model on datasets of various obstruction levels makes possible a measurement of the sensitivity of object detection to obstruction level.
The obstruction_fasterrcnn notebook walks users through authenticating with both the NVIDIA GPU Cloud, NGC, and Rendered.ai. Once the environment is set-up, the user installs the docker launcher, tao, and configures a mounts.json file to reflect the local file structure in the container.
With Rendered.ai’s SDK, ‘anatools’, the user can inspect the workspaces and datasets associated with their account. New accounts at Rendered.ai will come pre-populated with a batch of datasets for use with NVIDIA TAO.

The ‘anatools’ SDK is used to inspect the datasets in a workspace, download the datasets, and generate KITTI labels. Rendered.ai supports various application specific annotation formats including COCO, Pascal VOC, and KITTI. To integrate with NVIDIA TAO faster_rcnn, notebooks use KITTI annotation format.
The data is prepared for use with faster_rcnn by converting the annotations to Tensorflow Records. The TFRecords are created with the faster_rcnn command ‘dataset_convert’ which uses a specification file provided with the obstruction_fasterrcnn notebook. With the specification file, ‘frcnn_tfrecords_trainval.txt’, dataset_convert is instructed to use some percentage of the dataset, at random, for validation. Below shows typical numbers of each object class in the training data.

Cumulative Training Object StatisticsThe obstruction_fasterrcnn notebook downloads a ResNet-18 backbone from the NGC catalog for training. Similar to generating the TFRecords, the tao faster_rcnn command uses a specification file for training, which has all the individual toy classes listed. Another experiment might be to recognize a subset of the toys or map the toys to a single class; e.g., ‘toy’. The parameters in each of the specification files are described in the TAO Toolkit Documentation.


As shown in the code snippets above, evaluating the trained model is done with the same specification file as training. The parameters in ‘evaluation_config’ set the model and the ‘dataset_config’ is used to point to the testing images and tfrecords data directories. Evaluating several datasets are needed to scrutinize the ResNet model. The result of a typical experiment is shown where a linear regression analysis gives the mAP0.5 drops 1% for each 1.3% obstruction level.

With `tao faster_rcnn inference`, the user visualizes inferences allowing for further exploration. For example, one object class might have a relatively low AP score and some inferences show a particular style are sometimes missed. The user can go to Rendered.ai and change the graph to test a hypothesis. Perhaps adding training data that has more objects of that missing style will clean up the variance in the model. This is what we mean by closed-loop ML: based on model inferences, CV scientists establish evidence for a hypothesis that is testable by editing a graph to make either more training data or other test sets.
Conclusion
Using synthetic data to evaluate the sensitivity of a CV model demonstrates how the Rendered.ai platform can be used with NVIDA TAO to provide feedback in an ML pipeline. Even without a real dataset, closed-loop ML can be useful to measure sensitivity of a classification model to dataset features such as obstruction, disguised objects, or domain variation.
The ANA-TAO NGC Resource focuses on teasing out variance in a model trained on synthetic data. Rendered.ai also has style transfer functionality to support projects involving real data as well as dataset analytics to inform closing the gap between real and synthetic imagery. For more about how synthetic data can help you and to request access to the platform, contact Rendered.ai.
Rendered.AI | LinkedIn
Rendered.AI | 273 followers on LinkedIn. Physics Based Synthetic Data for visible and non-visible sensors.
www.linkedin.com

