Synthetic computer vision data is engineered or simulated data specifically designed to replicate the characteristics of real sensor data. Rendered.ai’s platform enables customers to create nearly unlimited fully labeled synthetic datasets for vision-based ML and AI applications.
Our expertise lies in helping customers to design and implement synthetic data applications that result in physically-accurate pixel and video content with 100% accurate annotation. We have helped diverse customers from satellite imagery consumers to medical, transportation, and security monitoring organizations.
Generate Simulated Data at Scale in the Cloud
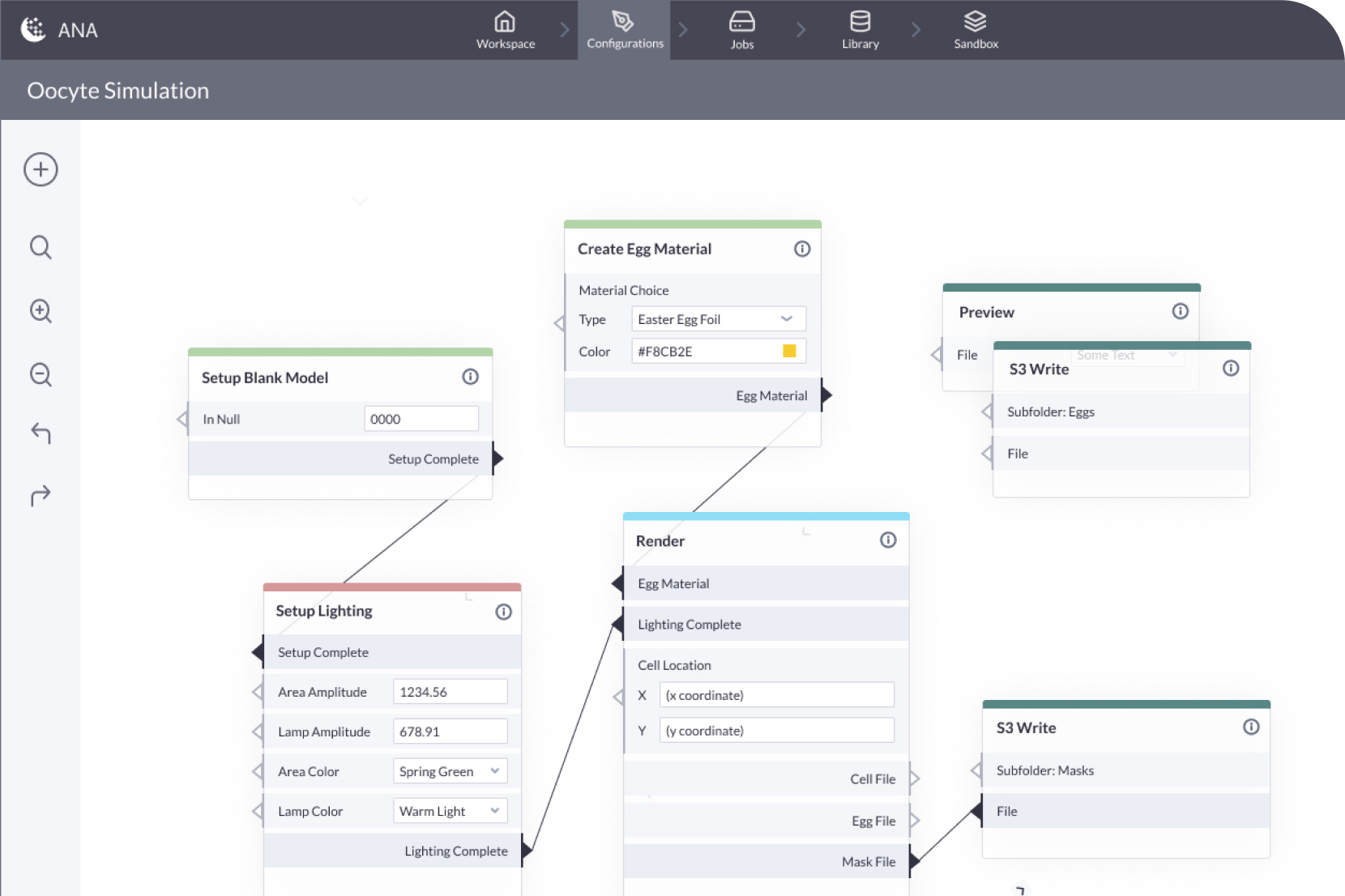
Through a combination of easy-to-use web experience, open APIs and SDKs, and the power of cloud infrastructure, the Rendered.ai platform puts tools for data generation, post processing, and dataset comparison in the hands of data science teams to enable them to create synthetic data that works for their project needs.
3D Simulation
Synthetic data generation starts by attempting to answer the question: What would be the ideal dataset needed to solve a problem? From that starting point, a digital twin of the sensor, sensor platform, scenarios, and environment are created to be able to simulate sensor data collection of imagery and video.

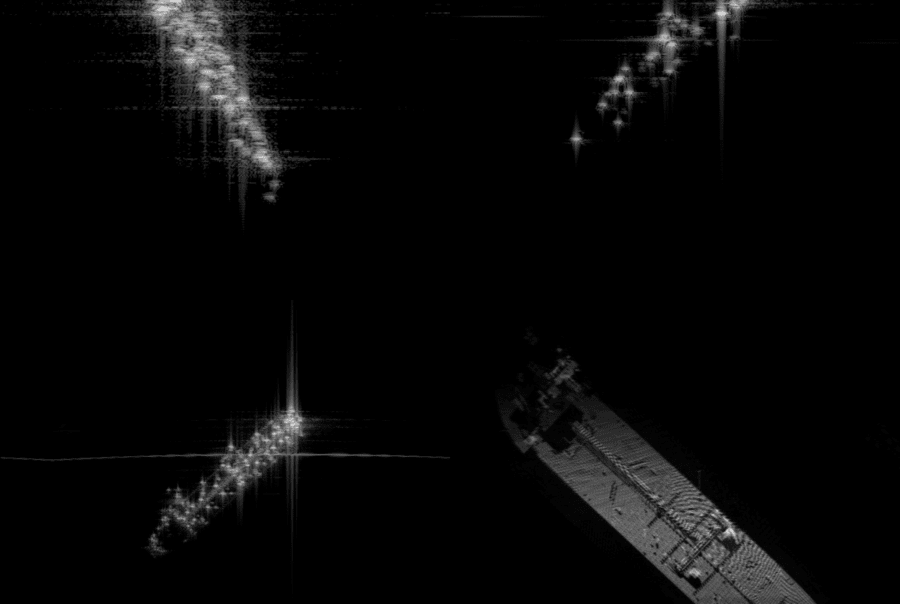
Physics-based Accuracy for Algorithms that Perform in the Real World
A synthetic data platform enables users to start with their best understanding of required data characteristics, then incorporate industry-standard simulation packages, 3D and 2D content, and computer graphics effects to create imagery and video that accurately emulate real sensor data capture.
Tools for Enhancing and Evaluating Synthetic Imagery
Using out-of-the-box platform tools for domain adaptation and dataset comparision, data science teams can investigate and iteratively improve datasets to attempt to create algorithms that perform as desired.

Collaboratively Manage Resources
Synthetic data generation is a team sport. With group-based collaboration built into our platform, users can share 3D models, annotation mapping files, dataset configurations, and much more.
Helping You Achieve Success With Synthetic Data

Replicate Real Data, Increase Diversity
Take advantage of our expertise in 3D modeling and simulation skills for synthetic data design, onboarding with our platform, professional services, and custom educational resources.

Built to Generate Data at Scale
Use a purpose-designed experience on top of industry-standard cloud infrastructure for collaborative dataset generation, management, and distribution.

Integrated into your Data Pipeline
Access and connect to open SDKs and APIs for configuring and generating dataset runs from remote systems, then retrieve datasets automatically when complete.
FAQs
Why do computer vision teams use synthetic data instead of real images?
Real data is:
- Time-consuming and expensive to acquire and label
- Often limited to common scenarios
- Ineffective in modeling for edge cases and rare objects
Synthetic data generation empowers engineering teams to design the training data they actually need, including rare events, foundational cases for experimentation, and diverse variations—before deployment.
Is synthetic data good enough to train real computer vision models?
Yes, when done correctly.
Low-fidelity synthetic data can actually hurt models. Well-labeled, physics-based synthetic data accelerates training, improves model performance, and fills data gaps left by real imagery.
Rendered.ai focuses on training-ready realism, not pretty marketing pictures.
Can synthetic data replace real data entirely?
Sometimes—but typically it is used to augment real data.
The winning formula for computer vision (CV) engineering:
- Generate customized synthetic data to bootstrap models quickly
- Extend training data to cover rare events synthetically
- Auto-label real data to effectively merge real and synthetic into robust training datasets
- Train CV models and infer performance on real-world test scenarios to inform data improvements.
- Iterate synthetic data generation to optimize model performance with the right mix of real-to-synthetic training data.
Synthetic data acts as a force multiplier, reducing engineering headaches, lost time, and dollars to insufficient training information for computer vision systems.
How does synthetic data generation with Rendered.ai help with data labeling?
Every synthetic image generated on the Rendered.a platform and by our team of experts on behalf of our customers is fully labeled at creation.
That means:
- Consistent, custom annotations mapped to desired format
- No tedious, time-consuming manual annotation
- Immediate ground truth for computer vision model training and evaluation
Rendered.ai also offers auto-annotation services for real data using models trained on synthetic datasets on the Rendered.ai platform — enhancing the value of existing datasets you’ve been waiting to use.
What computer vision engineering challenges benefit most from the effective use of synthetic data?
Synthetic data generated with Rendered.ai shines when:
- Training AI for rare events is important
- Sensors are complex (e.g., synthetic aperture radar, infrared, hyperspectral, multispectral, and x-ray)
- Cost, access, privacy-constraints, or risk limits real data collection
This comes up most often when engineering vision-based AI for:
4. Autonomous systems
5. Physical AI and robotics
6. Drones and counter-UAS defense systems
7. Satellite and aerial imagery
8. Manufacturing inspection
9. Maritime, transportation, and logistics
10. Security and surveillance
If you're having trouble training models for all the test scenarios and edge cases needed, working with complex sensor types, or filling a massive data gap, synthetic data probably belongs in your AI pipeline.
What sensor modalities can synthetic data support?
Rendered.ai supports RGB cameras and specializes in advanced modalities, that can be difficult to simulate and acquire viable real-world training data for, including:
- Synthetic Aperture Radar (SAR)
- Infrared (IR)
- Thermal
- Multispectral & hyperspectral
- X-ray
- Custom and emerging sensors
This is where more generic synthetic data vendors quietly tap out and Rendered.ai excels.
How is Rendered.ai different from other synthetic data providers?
There are 3 things most synthetic data vendors don’t do well—Rendered.ai does by default:
1. Physics-based accuracy
Images generated abide automatically by the laws of physics with respect to the interaction of lighting, materials, sensor physics, and geometry in each scene.
2. Sensor-specific simulation, specializing in difficult-to-work-with sensor modalities
Not just “an image,” — the accurate view of what your sensor would see. While this may seem trivial for RGB cameras, it requires rich domain expertise and proven data generation technology to render physically accurate synthetic images for complex sensor types, such as radar (e.g., SAR), infrared/thermal, remote sensing (e.g., multispectral and hyperspectral), and x-ray.
3. A data generation platform with engineering-first workflows
Synthetic data generation + model training + validation on one platform. The full synthetic data generation factory — instead of just a toolkit or engine you still need to build out. Rendered.ai’s PaaS provides open framework to plug in preferred tools, best-in-class simulator integrations (e.g., DIRSIG™, NVIDIA Omniverse, QSIM RT x-ray simulator), easily configured automated generation workflows, and direct access to customization tools, asset management, model training, and validation designed for streamlined computer vision engineering collaboration.
How fast can synthetic datasets be generated?
Minutes to days—not months.
CV engineering teams use Rendered.ai to:
- Spin up fully labeled, training-ready datasets at lightning speed
- Iterate training imagery with trackable history for future reuse
- Regenerate data quickly when new requirements arise
- Test models before hardware or sensors are deployed
The speed and quality that Rendered.ai provides is the competitive advantage you need to get your CV systems to market faster, minus extensive rounds of trial and error and the need to add expertise to your team.
Does synthetic data reduce AI development costs?
Exponentially so.
Rapid synthetic data generation with Rendered.ai:
- Overcomes the need for on-team domain expertise
- Reduces reliance on hard-to-acquire real-world data collection
- Cuts labeling costs and time
- Shrinks the likelihood of late-stage model failures
- Significantly shortens time-to-deployment
Most teams don’t realize how much budget they’re burning on data until the end of the project and inevitably choose to stop doing it the hard way.
Can synthetic data be customized to my exact use case?
100%! No computer vision model today performs perfectly across every use case. Without tailoring both the model and the data it’s trained on, specialized AI applications simply don’t work at scale.
Rendered.ai allows teams to customize:
- Environments
- Objects of interest
- Sensor specifications
- Distractors
- Viewing geometry
- Weather, lighting, occlusion
- Edge cases and rare conditions
You don’t adapt your model to the dataset—the dataset adapts to your model.
Is synthetic data secure and safe for proprietary projects?
Yes. Sometimes simulated data is the only option you have.
Because data is generated—not collected from the real world—it avoids:
- Non-compliance with privacy regulations (e.g., patients, children, consumers, etc.)
- 2. Restrictions tied to moving real imagery between systems
- Risky or dangerous real-world capture (e.g., imagery from conflict zones, battlefronts, and other unsafe environments)
When access to sensitive real-world test scenarios is challenging, synthetic data is often the only option in early-stage development of AI applications in fields like healthcare, defense, workplace safety, consumer retail, transportation, and more.
Is synthetic data only for large enterprises?
It doesn't have to be.
In fact, smaller teams benefit even more from using tools like Rendered.ai’s Synthetic Data Platform or Synthetic Data as a Service training data creation because they:
- Have fewer resources for data collection
- Need faster iteration
- Can’t afford long model retraining cycles
Rendered.ai’s solutions are designed to be accessible and easy-to-use for small engineering teams with the ability to quickly scale for enterprise deployments without changing their tech stack.
How much does synthetic data cost for computer vision?
Rendered.ai offers both subscription-based pricing for its Synthetic Data Platform as a Service and custom, project-based pricing for fully managed services like Synthetic Data as a Service, Model Development, and Auto-Data Labeling. This flexible structure allows teams to choose between hands-on platform use or expert-led delivery with minimal internal lift.
Rendered.ai Solution | What It Includes | How Pricing Works | Best For |
| Rendered.ai Platform as a Service (PaaS) | Enterprise platform to generate physically accurate, fully labeled synthetic data; configure automated generation workflows; manage datasets and assets; iterate scenarios; collaborate across teams | Subscription-based pricing starting at $5,000/month (Teams) and $15,000/month (Organizations). Self-managed and other custom deployments available by quote. | Teams that want ongoing control over synthetic data generation, iteration, and scaling |
| Synthetic Data as a Service (SDaaS) | Expert-led creation of custom synthetic datasets, including scenario design, sensor modeling, labeling, and delivery | Project-based pricing, scoped by dataset size and sensor modality | Organizations that want high-quality synthetic data customized and delivered quickly with minimal internal effort |
| Model Development Services | End-to-end computer vision model development using synthetic + real data, including training, tuning, and validation | Custom engagement pricing, typically structured by project scope or development sprints | Teams that need production-ready models without building the pipeline themselves |
| Auto-Data Labeling Services | Automated labeling of real-world data using synthetic-trained models and domain-specific annotation formats | Custom pricing, based on data volume and annotation type | Teams with large unlabeled datasets who need fast, accurate annotations at scale |
Please refer to our Pricing page or contact us to get a quote based on your computer vision needs.

